
20.1MB

1.32MB
Web Scraper是一款非常好用的网络爬虫插件,可以帮助用户轻松抓取网站上的所有数据内容,用户根本不需要编写任何代码。Web Scraper适用于各类网站,还支持将抓取的内容导出为CSV格式文件。有需要的用户可以快速下载。

Web Scraper功能
一个简单的网络爬虫插件,可以帮助不懂代码的用户实现数据抓取功能。有了这个扩展,你就可以创建一个sitemap(站点地图),包括如何遍历网站,应该提取什么内容。
有了这些网站地图,Web Scraper将导航网站并相应地提取所有数据。
稍后,您可以将过滤后的数据导出到CSV。
使用Web Scraper的教程
1.在标签页输入【chrome:http://extensions/】进入chrome扩展。解压你在这个页面下载的Web Scraper插件,拖拽到扩展页面。2.插件安装后,其按钮标记会出现在浏览器中。用户可以先在设置页面设置插件的存储设置和存储类型功能。
3.用户可以使用Web Scraper插件抓取页面。其操作方法如下:
1)、打开你要抓取的网页。
首先,要使用插件提取网页数据,需要在开发者工具模式下使用。使用快捷键Ctrl+Shift+I/F12或右键单击并选择“检查”。你可以在开发者工具下看到WebScraper的标签。如下图所示:

2)创建一个新的站点地图。点击创建新的站点地图,有两个选项。导入网站地图是一个现成的网站地图指南。我一般没有现成的sitemap,所以一般不会选这个,就选创建sitemap。

然后做这两个操作:
(1)站点地图名称:表示这个站点地图适用于哪个网页,所以可以根据网页来命名,但是需要用英文字母。比如我抓到今日头条的数据,就给它取名为头条;
(2)Sitemap URL:将网页链接复制到Star URL的列中。例如,在图片中,我将吴晓波频道的主页链接复制到了这个栏目,然后点击下面的创建站点地图来创建一个新的站点地图。
3)设置这个站点地图
整个Web刮刀的抓取逻辑如下:设置一级选择器,选择抓取范围;在主选择器下设置辅助选择器,选择捕获字段,然后选择捕获。
对于一篇文章来说,一级选择器意味着你要圈出这篇文章的元素,可能包括标题、作者、发表时间、评论数等。,然后我们会在二级选择器里挑出我们想要的元素,比如标题,作者,阅读次数。
我们来拆解一下设置一级和二级选择器的工作流程:

(1)单击“添加新选择器”创建一级选择器。
然后按照以下步骤操作:
输入ID: ID表示您正在抓取的整个范围。比如这里是文章,我们可以命名为wuxiaoboarticles;
选择类型:类型表示您正在抓取的该部分的类型,例如元素/文本/链接。因为这是整篇文章元素选择,所以我们需要先用element整体选择(如果这个网页需要滑动加载较多,那么选择element向下滚动);
勾选多个:勾选多个前面的小方框,因为你要选择多个元素而不是单个元素。当我们检查时,爬虫插件会帮助我们识别多个相似的文章;
设置:其余未提及的部分将保持默认设置。
(2)单击“选择”选择范围,并遵循以下步骤:
选择范围:使用鼠标选择要对数据进行爬网的范围。绿色为待选区域,用鼠标点击后变为红色,则此区域被选中;
多选:不要只选一个,也要选下面一个,否则爬出来的数据只有一行;
选择:记得完成选择;;
保存:单击保存选择器。
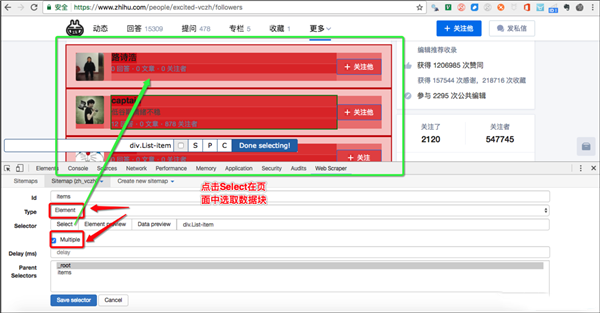
(3)设置完这个一级选择器后,点击设置二级选择器,按照以下步骤操作:
新建选择器:单击添加新选择器;
输入ID: ID代表你抓取的是哪个字段,所以可以取那个字段的英文。比如我要选“作者”,我就写“作家”;
类型:选择文本,因为你要抓取的是文本;
不要勾选多个:不要勾选多个前面的小方框,因为我们是来抓取单个元素的;
设置:其余未提及的部分将保持默认设置。

(4)单击选择,然后单击要爬网的字段,并按照以下步骤操作:
选择字段:此处爬取的字段是单个的,用鼠标点击字段即可选择。比如你要抓取标题,用鼠标点击一篇文章的标题,当该字段所在的区域变红时就会被选中;
选择:记得完成选择;;
保存:单击保存选择器。

(5)重复上述操作,直到选定要攀爬的场地。
4.抓取数据
(1)之后,如果你想抓取数据,你只需要设置所有选择器为start:
单击“刮擦”,然后单击“开始刮擦”。弹出一个小窗口后,爬虫就会开始工作。你会得到一个包含你想要的所有数据的列表。
(2)如果你想对这些数据进行排序,比如按阅读量、点赞、作者等指标排序,让数据更加一目了然,那么你可以点击导出数据为CSV,导入到Excel表格中。
(3)导入Excel表格后,可以过滤数据。

这里我们只是简单介绍和总结一下Web Scraper插件的功能、安装和一个简单的单页例子。其实刮网器的作用远不止于此。事实上,它还可以抓取分页、多个页面和元素以及二级页面。





















 keep怎么投屏到电视上_keep如何投屏到电视上
keep怎么投屏到电视上_keep如何投屏到电视上 微博怎么找手机通讯录好友 微博找通讯录好友方法
微博怎么找手机通讯录好友 微博找通讯录好友方法 keep怎么拿奖牌_keep奖牌在哪里跑
keep怎么拿奖牌_keep奖牌在哪里跑 哈啰顺风车如何预约打车_哈啰顺风车预约打车方法
哈啰顺风车如何预约打车_哈啰顺风车预约打车方法 keep添加通讯录好友方法_keep如何添加通讯录好友
keep添加通讯录好友方法_keep如何添加通讯录好友 搜狗输入法怎么设置快捷短语_快捷短语设置方法
搜狗输入法怎么设置快捷短语_快捷短语设置方法 酷狗直播提成比例是多少_酷狗直播分成比例一览介绍
酷狗直播提成比例是多少_酷狗直播分成比例一览介绍 英雄联盟魅惑女巫2022皮肤预览
英雄联盟魅惑女巫2022皮肤预览





























